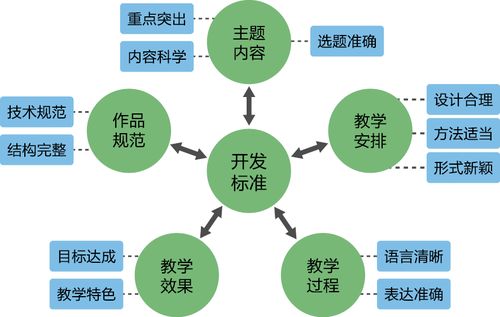
知識圖譜與大模型融合在醫(yī)學研究與試驗發(fā)展領域的應用與前景
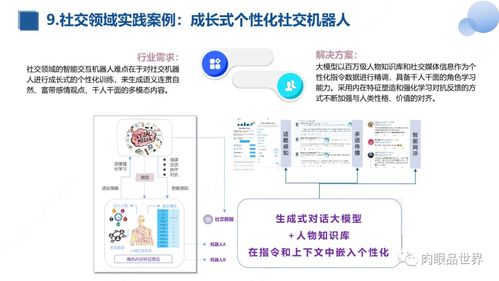
隨著人工智能技術的飛速發(fā)展,知識圖譜與大模型作為兩大核心技術,正逐步在醫(yī)學研究與試驗發(fā)展領域展現(xiàn)出強大的融合潛力。醫(yī)學研究具有數(shù)據(jù)復雜、知識體系龐大、對精準度要求極高等特點,將結構化、可推理的知識圖譜與具備強大語言理解與生成能力的大模型相結合,有望推動醫(yī)學發(fā)現(xiàn)、臨床試驗、藥物研發(fā)等關鍵環(huán)節(jié)的范式革新。
知識圖譜在醫(yī)學領域的應用已較為成熟,它通過構建實體(如疾病、基因、藥物、癥狀)及其關系(如治療、引發(fā)、抑制)的網(wǎng)絡,將海量、多源的醫(yī)學知識進行系統(tǒng)化、結構化整合。例如,在藥物研發(fā)中,知識圖譜可以清晰展示藥物靶點、作用通路、副作用關聯(lián)等信息,輔助研究人員理解藥物作用的復雜機制,并預測潛在的藥物相互作用或不良反應。在臨床試驗設計階段,知識圖譜能幫助精準篩選受試者群體,通過分析患者的基因型、病史、合并癥等關聯(lián)信息,確保試驗人群的同質(zhì)性與代表性,從而提高試驗的效力和安全性。
傳統(tǒng)的知識圖譜也存在局限性,例如構建和維護成本高、難以處理非結構化文本中的隱含知識、動態(tài)更新較慢等。這正是大語言模型可以彌補之處。大模型經(jīng)過海量文本(包括醫(yī)學文獻、電子病歷、科研報告)的預訓練,具備了深厚的醫(yī)學語境理解能力和強大的信息抽取與生成能力。它能夠從非結構化的文本中自動提取實體和關系,輔助或自動化知識圖譜的構建與更新。更重要的是,大模型能夠理解復雜的自然語言查詢,并以人性化的方式與研究人員交互,充當一個智能的醫(yī)學知識問答與推理助手。
二者的融合實踐正在多個層面展開:
- 增強知識獲取與構建:大模型可以作為“前端”處理器,自動閱讀最新的醫(yī)學文獻、臨床試驗報告,提取關鍵實體和關系,并建議或自動更新到現(xiàn)有的醫(yī)學知識圖譜中,極大提升了知識體系的時效性和完備性。
- 賦能智能檢索與問答:融合系統(tǒng)能夠理解研究人員提出的復雜、多跳問題。例如,當查詢“某種新發(fā)現(xiàn)的基因突變可能通過哪些通路影響特定癌癥的進展,并且有哪些已上市藥物可能對其有潛在抑制作用?”時,系統(tǒng)可以利用大模型解析問題意圖,然后驅(qū)動知識圖譜進行多步推理和路徑查找,最終生成結構清晰、證據(jù)鏈完整的答案,而不僅僅是返回一系列相關文檔。
- 輔助假設生成與試驗設計:這是融合最具價值的場景之一。系統(tǒng)可以基于知識圖譜中已有的因果關系網(wǎng)絡,結合大模型對前沿研究和失敗案例的“理解”,提出新的、可驗證的研究假設。例如,通過分析疾病A與基因B、通路C的已知關聯(lián),以及藥物D對通路C的調(diào)節(jié)作用,系統(tǒng)可能推斷“藥物D或可改善疾病A的某種亞型”,為研究人員提供全新的探索方向。它可以根據(jù)假設,智能推薦臨床試驗的分組方案、觀察指標和潛在風險點。
- 優(yōu)化數(shù)據(jù)管理與分析:在臨床試驗進行中,產(chǎn)生的數(shù)據(jù)是海量且多維的。融合系統(tǒng)可以利用知識圖譜對試驗數(shù)據(jù)進行語義層面的關聯(lián)和建模,再借助大模型的分析與報告生成能力,實時監(jiān)測試驗進展,自動生成數(shù)據(jù)洞察報告,甚至提前預警異常趨勢。
盡管前景廣闊,融合實踐也面臨挑戰(zhàn):醫(yī)學知識的嚴謹性要求極高,大模型的“幻覺”問題必須通過知識圖譜的嚴格約束來緩解;數(shù)據(jù)隱私與安全,尤其是在處理患者數(shù)據(jù)時,是必須跨越的倫理與法規(guī)門檻;需要既懂醫(yī)學又懂人工智能的復合型人才來驅(qū)動和評估這些系統(tǒng)。
知識圖譜與大模型的深度融合,將不僅僅是醫(yī)學研究的輔助工具,更可能成為驅(qū)動下一代“AI驅(qū)動的醫(yī)學發(fā)現(xiàn)”的核心引擎。它將使醫(yī)學研究從基于經(jīng)驗的試錯模式,加速轉(zhuǎn)向基于全息知識網(wǎng)絡與智能推理的精準預測模式,最終為攻克復雜疾病、加速新藥研發(fā)、實現(xiàn)個性化醫(yī)療帶來革命性的突破。
如若轉(zhuǎn)載,請注明出處:http://www.wessel.cn/product/47.html
更新時間:2026-05-29 15:59:55